System Architecture
Status: In Progress
| Date | Version | Author | Description |
|---|---|---|---|
| 2024-12-12 | 0.1 | Iskander | Initial draft |
The system is designed to be a distributed system that is scalable, resilient, and secure. The system architecture is based on the following principles:
- Microservices: The system is designed as a set of loosely coupled services that are independently deployable and scalable. Each service is responsible for a specific business capability and communicates with other services using well-defined APIs.
- Event-Driven: The system is designed to be event-driven, where services communicate with each other through events. This enables asynchronous communication between services and allows for decoupling of services.
- Resilient: The system is designed to be resilient to failures by implementing retry mechanisms, circuit breakers, and other resiliency patterns. This ensures that the system can recover from failures and continue to operate under adverse conditions.
- Scalable: The system is designed to be scalable by using horizontal scaling techniques such as load balancing, sharding, and partitioning. This allows the system to handle increasing loads and scale out as needed.
- Secure: The system is designed to be secure by implementing security best practices such as authentication, authorization, encryption, and auditing. This ensures that the system is protected from unauthorized access and data breaches.
- Observability: The system is designed to be observable by implementing monitoring, logging, and tracing capabilities. This allows operators to monitor the system’s health, diagnose issues, and troubleshoot problems.
- Automated: The system is designed to be automated by using infrastructure as code, continuous integration, and continuous deployment practices. This allows for rapid and reliable deployment of changes to the system.
- Cloud-Native: The system is designed to be cloud-native by leveraging cloud services such as compute, storage, networking, and databases. This allows the system to take advantage of the scalability, reliability, and cost-effectiveness of cloud platforms.
- Open Standards: The system is designed to use open standards and protocols to ensure interoperability, portability, and flexibility. This allows the system to integrate with other systems and services using well-established standards.
- Modular: The system is designed to be modular by using a modular architecture that allows for easy extensibility, maintainability, and reusability. This allows developers to add new features, fix bugs, and refactor code without affecting other parts of the system.
- Performance: The system is designed to be performant by optimizing for speed, throughput, and latency. This ensures that the system can handle high volumes of traffic, process requests quickly, and respond to users in a timely manner.
Runtime Architecture
The main runtime architecture is based on a client-server model. Human actors interact with the system through a web-based user interface (UI) or a mobile application. The UI applications a,d any other third-party applications, communicate with the system through a set of APIs exposed by the backend services.
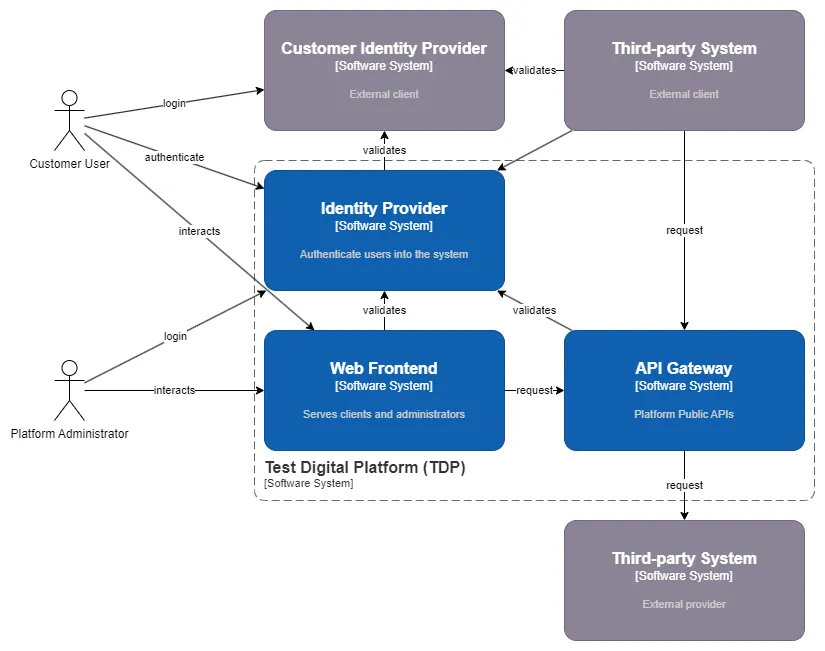
- Test DigitalPlatform (TDP): Represents the set of services that are controlled by the production team. These services are responsible for handling user/client authentication, serving Web and Mobile Applications, serving API requests, and monitoring the system’s health. The TDP system interacts with external users and services through a set of UIs and APIs.
Runtime Actors
The user that are going to interact with the system at runtime can be classified into the following roles:
- Platform Administrator: They are responsible for managing the system functionality, configuring settings, attending complex user requests in user’s behalf, creating technical issues for the maintenance team. They have access to all the system’s features and functionalities. Product Managers and System Administrators are part of this team.
- Platform Maintenance Team: They are responsible for monitoring the system’s health, diagnosing issues, troubleshooting problems, and performing maintenance tasks. They have access to the system’s monitoring and diagnostic tools. Project Managers and Developers are part of this team.
- Customer Administrator: They are responsible for managing the customer’s account, configuring settings, creating and managing users, and attending user requests. They have access to the customer’s account settings and user management features.
- Customer User: They are the end-users of the system who interact with the system to perform their tasks. They have access to the customer’s account features and functionalities.
Runtime Interfaces
The main interfaces of the system are:
- Web Application: The web application is the main user interface for the system. It allows users to interact with the system, view data, perform actions, and manage their account settings. The web application communicates with the backend services through the API gateway.
- Mobile Application: The mobile application is an alternative user interface for the system. It allows users to interact with the system on mobile devices, view data, perform actions, and manage their account settings. The mobile application communicates with the backend services through the API gateway.
- API Gateway: The API gateway is responsible for routing requests from the web and mobile applications to the appropriate backend services. It acts as a reverse proxy, load balancer, and security gateway for the system’s APIs. The API gateway enforces security policies, rate limiting, and authentication for incoming requests.
- Identity Provider: The identity provider is responsible for managing user authentication and authorization. It provides user authentication services, issues access tokens, and validates user credentials. The identity provider integrates with external identity providers using standard protocols such as OAuth 2.0, OpenID Connect and SAML 2.0.
- Monitoring Platform: The monitoring platform is responsible for collecting, storing, and analyzing system metrics, logs, and traces. It provides real-time visibility into the system’s health, performance, and availability, as well as alerts and notifications for critical events.
Runtime Data Flows
User Authentication Flow
TBD
User Request Flow
All authenticated user requests through the web and mobile applications follow the same data flow:

- The user interacts with the frontend to perform an action or request data by opening a page, clicking a button, or submitting a form.
- The frontend sends a request to the API Gateway with the user’s credentials and the requested action.
- The API Gateway sends a validation request to the Identity Provider to verify the user’s credentials.
- The Identity Provider validates the user’s credentials and accepts or rejects the request.
- If the request is accepted, the API Gateway forwards the request to the appropriate backend service.
- The backend service processes the request, retrieves data from the database, performs business logic, and generates a response.
- The backend service sends the response back to the API Gateway.
- The API Gateway forwards the response to the frontend.
- The frontend displays the response to the user, updates the UI, and notifies the user of the result.
There are different types of requests that the user can perform, and each have different data flows.
Query Data Flow
A query is a piece of information the user need to make a decision on what to do or ask next. This information should be available to the user as quickly as possible to keep the user engaged. So any type of aggregation or computation required to generate the data should be done in the backend and should be optimized to be as fast as possible.
Usually the user will hint with some filtering, sorting and pagination criteria to get the data they need. The backend service will receive this criteria and will use it to query the database and return the data to the user. There are techniques to optimize this process like caching, indexing, and denormalization. The implementation of each query must be designed to be as fast as possible, using conventions that will be gathered in this documentation in the source code guides.
Once the request has arrived to the corresponding backend service, the data flow must be as simple as possible, like shown in the following diagram:

- The backend service fetch data from the database or the external service using the query criteria.
- The backend service processes the data, applies business logic, and generates a response.
- The backend service sends the response back to the client that requested the data.
Command Data Flow
Commands carry intent from the user or from the business automated processes. The user can perform actions like creating, updating, or deleting data. The business processes can perform actions like sending notifications, generating reports, cleaning up data, etc.
Depending on the functional definition of the command and the technical requirements, the command must be implemented following the conventions that will be gathered in this documentation in the source code guides.
Once the request has arrived to the corresponding backend service, the data flow must be as simple as possible, like shown in the following diagram:

- The backend service fetch data from the database or the external service. Multiple fetch operations could be required to get all the data needed to perform the command.
- The backend service processes the data, applies business logic, and decides on the action to take.
- The backend service performs stores the consequences of the decision in the database or the external service.
- The backend service sends the response back to the client that requested the data.
- The backend service sends notifications to the interested parties.
This command pattern is the simplest one, where the operations can be done in a single transaction. There are more complex patterns that require multiple steps to be completed, like sagas, workflows, and state machines. These patterns will be documented in the source code guides.
Process Data Flow
Processes are operations that can be triggered by requests other than the user or a third-party service. The core implementation can be similar to the command pattern, but it could have a triggering API different than the typical request-response API. So instead of a REST API, it could be a message queue, a webhook, a scheduled job, etc.
Also, it is recommended that a process use existing commands to implement its purpose. This way, the process can be implemented as a simple orchestrator of commands, and the commands can be reused in other processes or in the user interface.
Static Architecture
TBD: Describe the static architecture of the system, including the components, layers, modules, and dependencies.
Deployment Architecture
TBD: Describe the deployment architecture of the system, including the infrastructure, environments, deployment pipelines, and deployment strategies.